
One of the most notable new APIs in Eclipse Photon is called Code Mining. A code mining represents content (i.e. labels and icons) that are shown within the text editor, but are not part of the text itself. For example, within a method call statement a mining could display the name of parameters, or an icon above unit test methods could be shown that runs the test on clicking it.
The following image illustrates such minings in Java code. The code minings are provided by the jdt-codemining Plug-in, which the API’s inventor Angelo Zerr is developing on GitHub. This will eventually be contributed to JDT when it is mature enough.

Code Mining is a generic extension to text editors in Eclipse. The actual text to be displayed depends on the concrete language. It is up to the developers of the language tooling to implement the interface org.eclipse.jface.text.codemining.ICodeMiningProvider and to register the provider with the org.eclipse.ui.workbench.texteditor.codeMiningProviders extension point.
Xtext’s integration of the Code Mining API
With version 2.14 the Xtext project offers an integration with the Code Mining API. The API is provided by the new plugin org.eclipse.xtext.ui.codemining. Xtext’s Domain-Model example has been extended to make use of this API and serves as a blue print for other languages.
First of all, the language’s generator workflow is extended to use the CodeMiningFragment:
import org.eclipse.xtext.xtext.generator.ui.codemining.CodeMiningFragment
...
Workflow {
...
language = StandardLanguage {
...
fragment = CodeMiningFragment {
generateStub = true
generateXtendStub = false
}
}
}
When the generator is executed it will create a <DSL>CodeMiningProvider stub class in the UI project and register it to the plugin.xml. The provider extends from AbstractXtextCodeMiningProvider, which implements the general contract of an ICodeMiningProvider.
The Code Mining feature distinguishes between minings that are shown above a mined text line (line header minings) and minings shown within a line (line content minings – like the Java example above). AbstractXtextCodeMiningProvider offers some convenience methods createNewLineHeaderCodeMining() and createNewLineContentCodeMining() to create appropriate instances of ICodeMining.
The developer’s task is to implement the createCodeMinings() method:
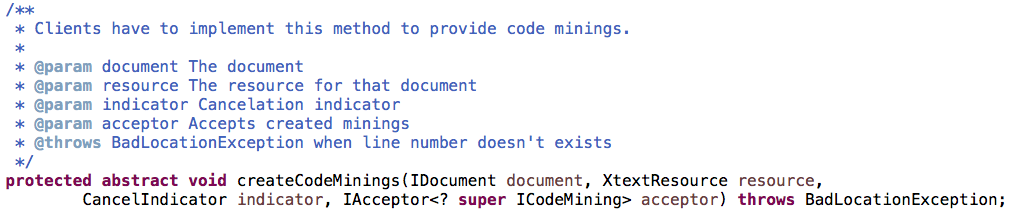
In this method basically the resource is analysed to identify text to be displayed for some elements. Then the location for that text in the document has to be computed. Usually this affects accessing the document or the node model using NodeModelUtils.
In the Domain-Model Example return types of operations are optional. When not declared, the return type is inferred. Therefore code minings could be created that display the inferred return type when not specified.
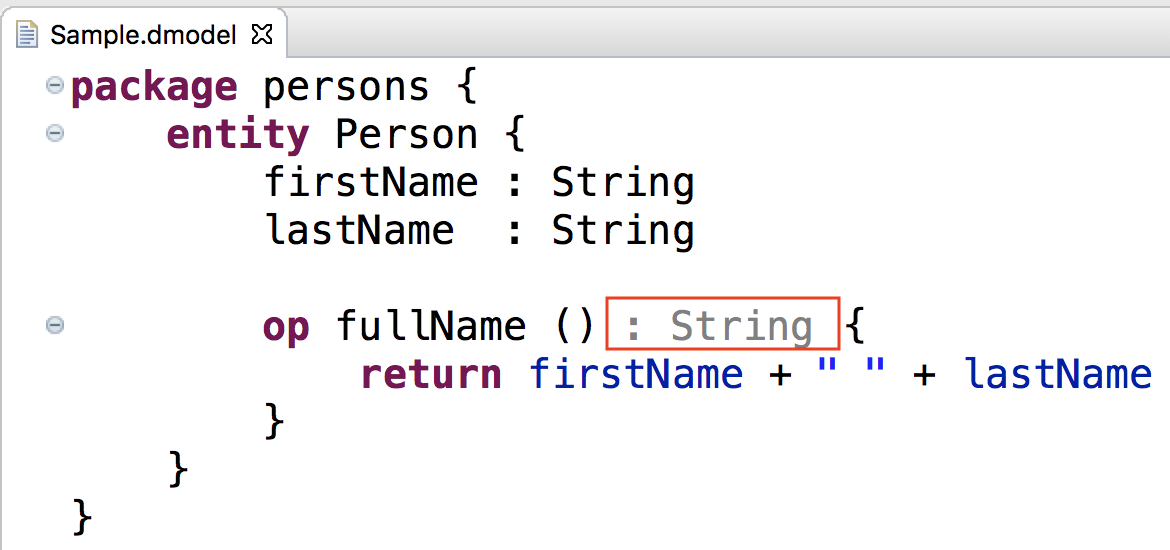
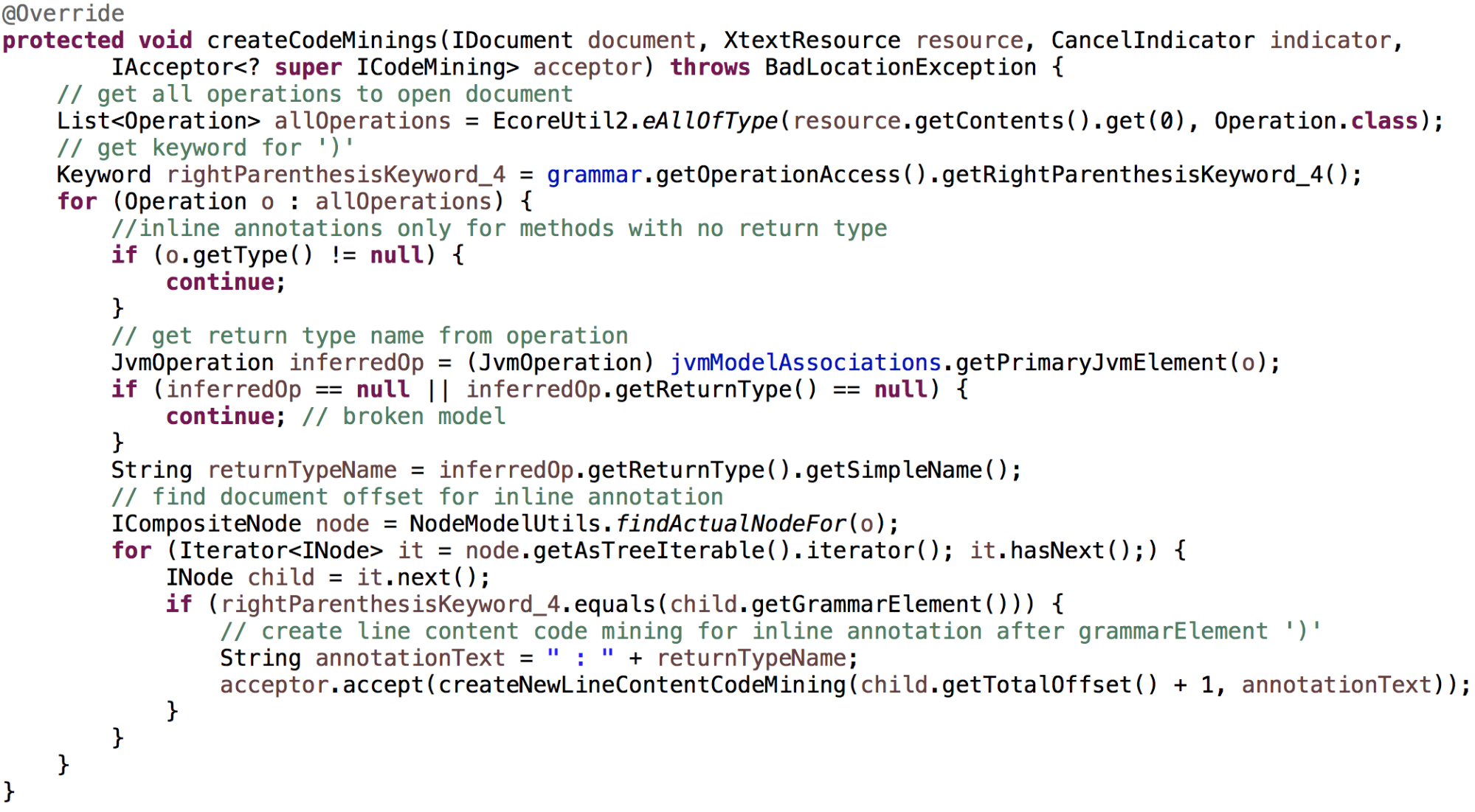
The example’s DomainmodelCodeMiningProvider class implements the createCodeMinings() method as follows: First, all Operation instances in the resource are collected. For each instance that doesn't have an explicit type set, the inferred return type’s name is computed. The type should be displayed after the closing parenthesis. The parenthesis’ Keyword is looked up in the grammar and stored in rightParenthesisKeyword_4. From the node model the node representing the parenthesis is searched to find the document offset where the text is to be displayed. Finally, the acceptor is called with a line content mining created from offset position and the inferred type name.
A look behind the scenes
Code Mining is an extension to JFace’s SourceViewer. The new interface ISourceViewerExtension5 defines the contract for code mining support in source viewers.
Xtext uses this extension in the XtextCodeMiningReconcileStrategy and calls the extension methods (mainly updateCodeMinings()) when the text in the editor is reconciled. Xtext’s main IReconcilingStratetgy implementation XtextDocumentReconcileStrategy was already aggregating two custom reconciling strategies, but not well prepared to add a third. It was refactored to aggregrate multiple now.
The XtextCodeMiningReconcileStrategy will only be added when code mining support is provided by a DSL. Thus there will be no overhead for any existing DSL until they implement code mining. Users will currently experience a small delay on the text update, since minings are computed and displayed asynchronously.
A note on backward compatility
The Xtext framework is backward compatible to older versions of the Eclipse Platform. With Xtext 2.14, the project still targets Eclipse Luna (4.4) as lowest supported platform to run on and is built and tested against it.
Since Code Mining is a new feature that's only provided on Eclipse Photon (4.8) and later, this raised some challenges on compatibility:
- Xtext must be buildable with Eclipse Luna as Target Platform
- DSLs developed on a 4.8+ Platform with Code Mining must be deployable on Eclipse Oxygen and earlier
- The DSL’s editor must run on Eclipse Oxygen and earlier without breakage, just the minings are not displayed
We'll highlight these challenges and how they were solved in Xtext in a later blog post.
Conclusion
Code Mining is a new feature in Eclipse text editors that can provide valuable context information to developers within displayed text. Xtext 2.14 adopts the Code Mining API and offers an own API suited for Xtext DSL implementations. A usage reference is contained in the Domain-Model example. DSLs providing a Code Mining implementation are safely installable on older Eclipse versions.
Kudos to Angelo Zerr, who has contributed the API to Eclipse Photon and was always helpful to solve issues that we faced with the API and its implementation. On itemis side, a huge part of the effort was done by student René Purrio, who carefully analyzed the implementation and did intensive testing. With tight cooperation with our Xtext core team he was able to shape a nice implementation and contribute a valuable feature to Xtext.
Comments