
Hi folks! Some of you might have seen my earlier blogpost on Machine Learning Formatting. It was more or less meant as an advertiser for the Eclipse Democamp Munich. As promised, here comes the follow up blogpost with more details.
Codebuff is a project started by Terrence Parr. The project aims the problem that writing a codeformatter is hard and will not fit all needs. Therefore people want to customize it in every way since formatting is a very individual thing.
Codebuff tries to format code by taking already formatted examples and learning out of that how to format code based on the same grammar. To do that it needs the corresponding lexer and parser. The lexer is used to get the tokens and the parser to create an abstract syntax tree out of the tokens. Based on that information Codebuff tries to mimics the behavior of a developer. Sounds simple, but how does that work? First of all code consists of tokens.
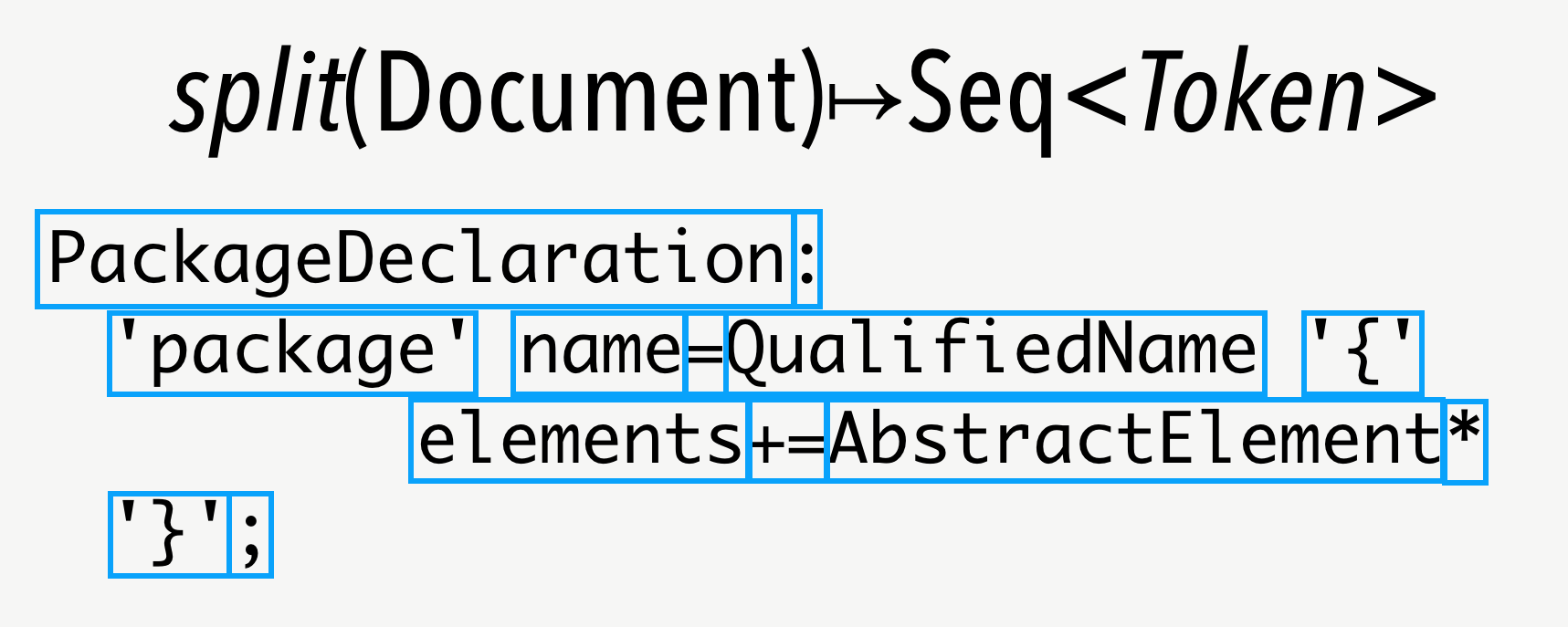
Depending on tokens and the location a developer would normally make a decision to introduce or delete whitespaces. A whitespace could be a simple space, a newline along with an indentation or alignment. Another valid decision could also be to do nothing. To make a decision you need certain criteria. Codebuff works with 21criterias, so called features that are taken into account. The following figure shows the 5 most obvious features.

Based on those 21 features Codebuff analyses the given examples and computes token properties.

When training is done all token properties are stored as vectors in a matrix along with the whitespace information.
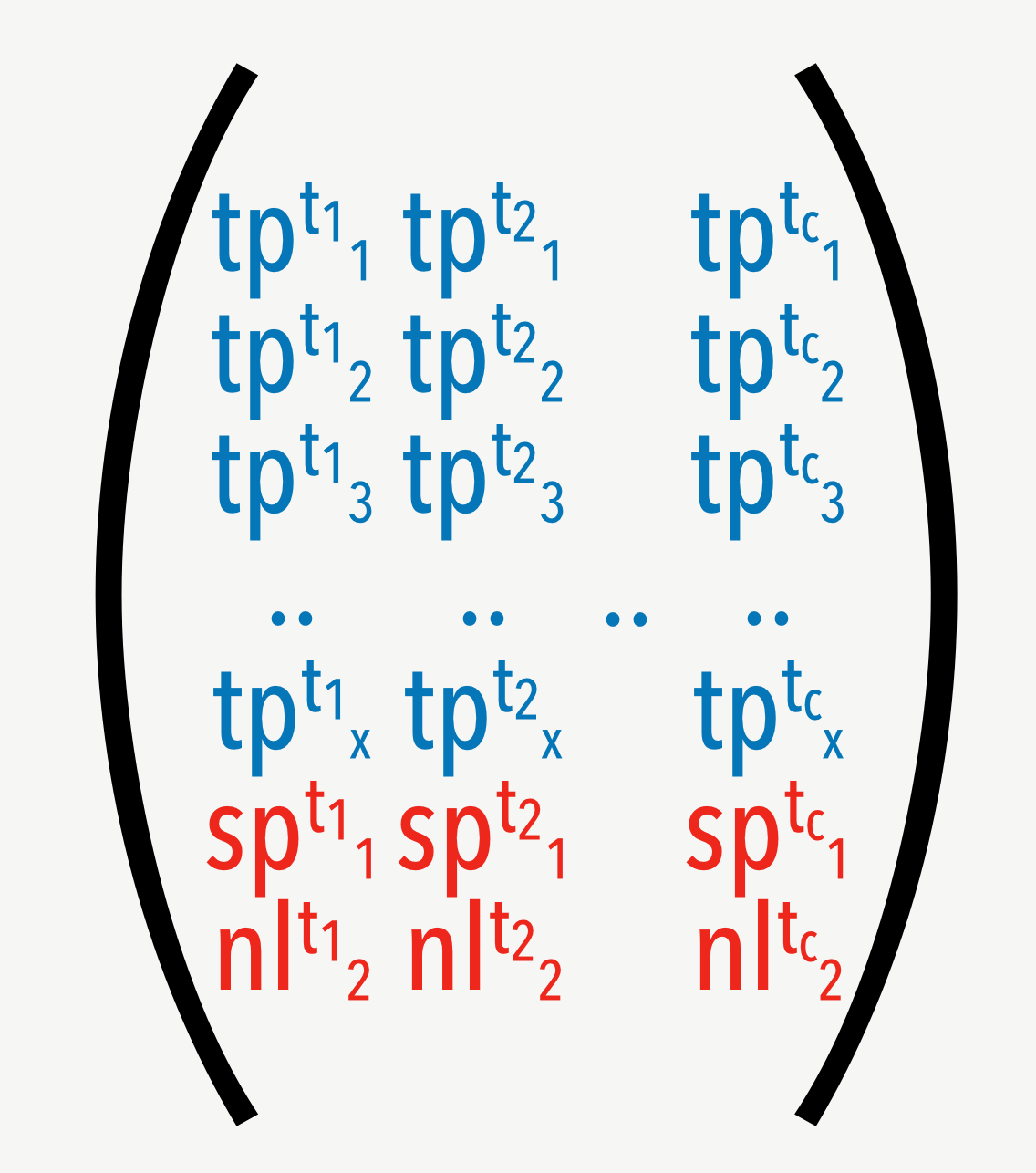
From this point on we should start to speak about machine learning. What we want to achieve is finding a match in the computed matrix of token properties and get the whitespace to inject into the given document at a certain position.
First of all we have to compute where to look at in the examples. For that reason we look at our current position in the document and compute the token property (vector) like we did it in the training without storing it to the matrix.
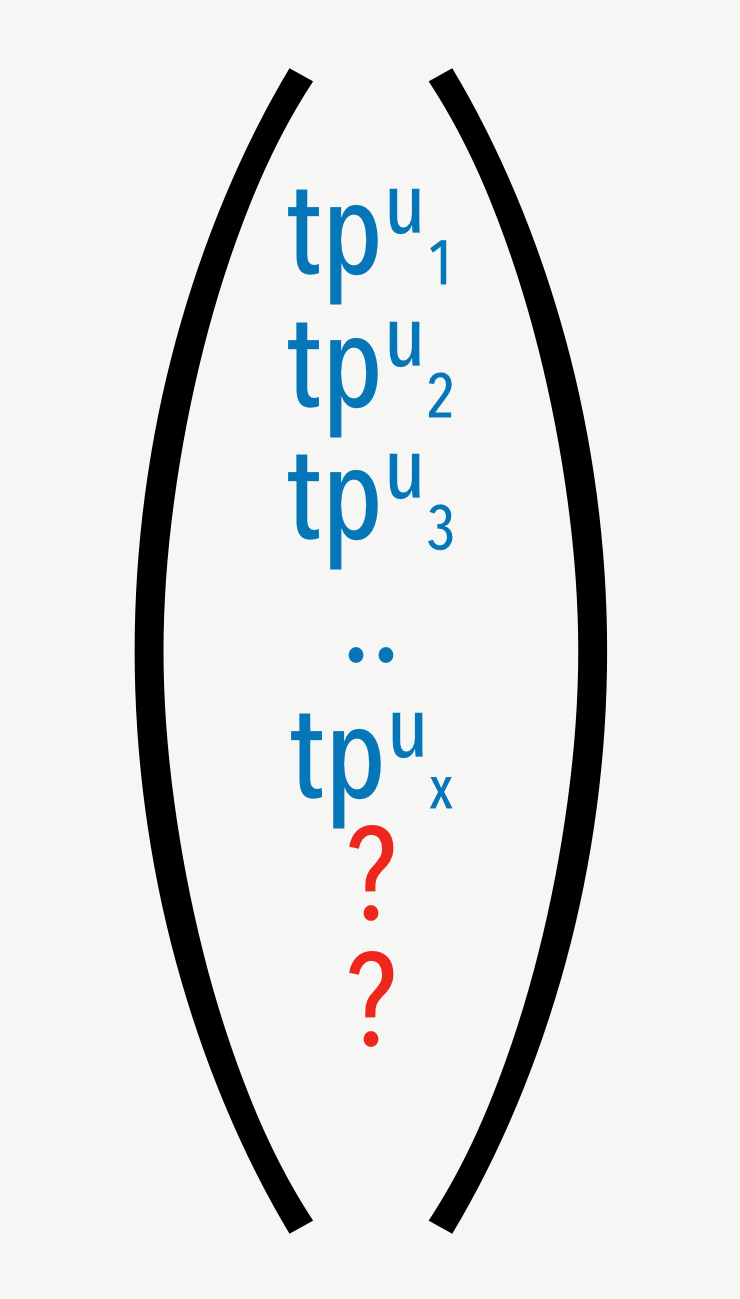
Now that we have that vector we need an algorithm to find a match in the matrix and apply the right whitespace to the document.

For doing that Codebuff uses the simplest machine learning algorithm that exists – the K-nearest neighbors algorithm. The algorithm uses a function to compare a token property to the entries of the existing training-matrix. To do that the a constant named k needs to be specified to define how many nearest neighbors should be used. Mostly k is computed once by taking the root of the number of examples in the corpus, but for Codebuff k is fixed to 11.
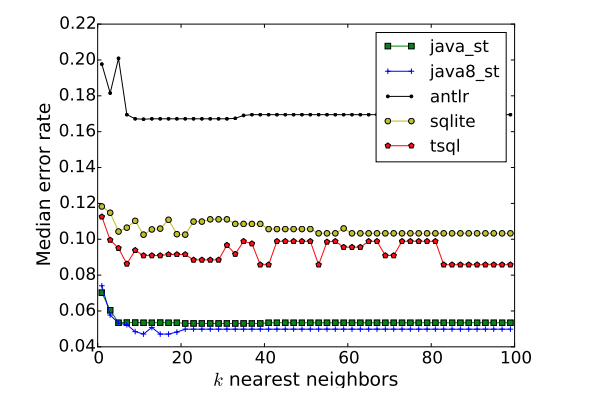
As shown above, experiments with different languages showed that the median error rate is nearly constant from k = 11 on, so taking this as a constant makes sense for performance reasons.
As we now know the value of k, we can start to find most similar token properties to the one we just computed at the location to format.

Out of that the algorithm uses a function to weigh the best whitespace. In Codebuff it takes simply the whitespace that appears most often – very simple but efficient. Codebuff's theoretical background is explained in more depth here and you can find an entertaining talk by Terence on YouTube.
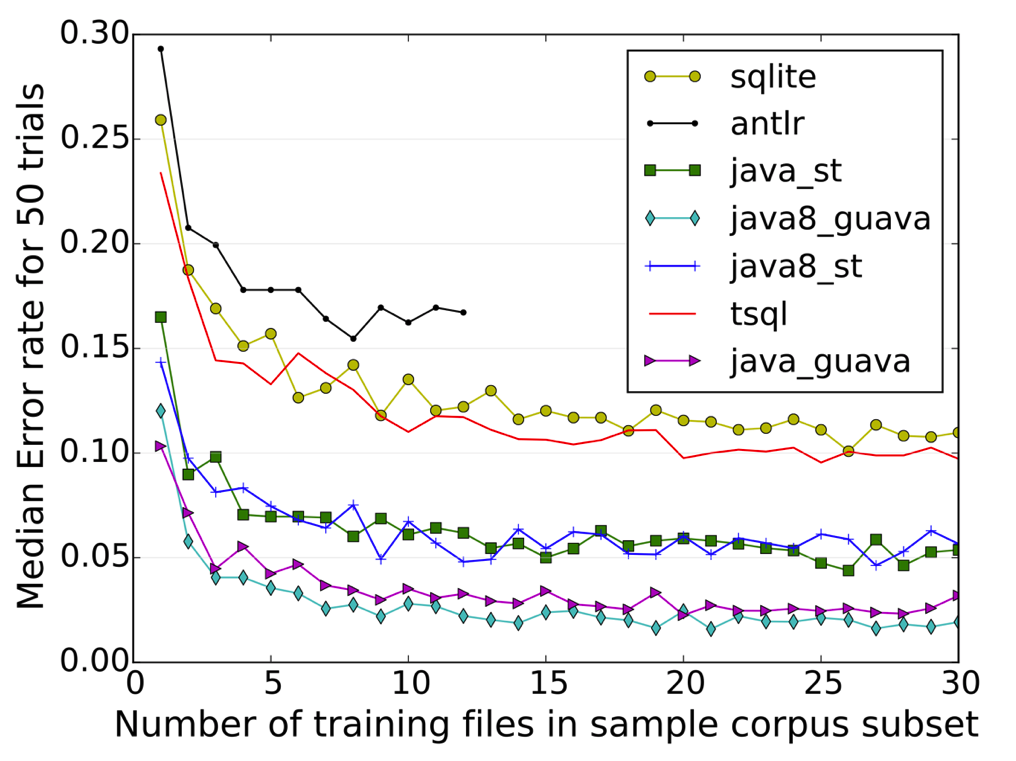
Looking at the way Codebuff works you might ask yourself how many example files you need to get good results? The answer is pretty simple: after a lot of experiments the Codebuff guys found out that from 10 example files on the results will not get better nor worst. The next figure shows for some different languages that after 10 files the error rate stays around the same.
So – what has Codebuff to do with Xtext?
Now as we know a bit of the theoretical background around Codebuff you may wonder what all that stuff has to do with Xtext.
In Xtext you can create various DSLs for very different domains. For each language you need to specify a formatter. Luckily Xtext comes with two different APIs. The older one relies on tokens only, that means you can define how your DSL should be formatted on a lexical level. The newer API relies on the semantic model in addition. Depending on the state of the abstract syntax tree you can treat things different. Cool – but customization of your formatter is not coming out of the box and we know that formatting is an individual thing. So you would end up in a lot of effort to write a reasonable formatter and make customizations possible. Even when you did your best you will always find a special case that someone wants to treat differently. Codebuff sounds like a nice idea to solve that problem...
To marry Xtext and Codebuff together you don't need to do much. Ok – Xtext relies on AntLR 3 and bringing AntLR 4 on the classpath will take you into hell, but there is a pragmatic way around that.
DISCLAIMER: From this point on we are talking about a prototype – not ready for production!
First we wrote a so-called GeneratorFragment. To understand this you would have to understand how Xtext works under the covers, but for now let's just stay with the fact that Xtext generates it's DSL specific infrastructure out of the Xtext grammar and a GeneratorFragment is one piece of the overall generator.
To come back to our issue – the GeneratorFragment needs to generate an AntLR 4 grammar. Out of that we need to generate the AntLR 4 lexer and parser. To do that we need the AntLR 4 generator but we are not allowed to bring that stuff on the classpath. Let's assume we managed to do that – how could we compile the generated code without AntLR 4 on the classpath? Even when we managed that we are not allowed to bring Codebuff on the classpath as it carries AntLR 4 under the covers. Even when we managed that – does Codebuff have an API that fits for us? The documentation just deals with a call of a main method with a bunch of parameters....
Ok – step by step.
1. Generate the grammar
The major difference between AntLR 3 and 4 is that AntLR 4 does not allow syntactic predicates anymore since it handles left recursion now directly. AntLR 3 is not able to do that and for that reason grammars need to be left refactored. By doing that, syntactic predicates guide the parser on it's way to get rid of ambiguities and make decisions. The other thing is that the syntax has changed a bit from AntLR 3 to 4. Beside that Codebuff has a special need. Whitespaces and comments need to go to the hidden channel.
2. Generate lexer and parser
To achieve that we are downloading the necessary jar on demand once, like we already do it in Xtext for AntLR 3. To invoke the so called Tool of AntLR 4 we created a URLClassLoader that points to the jar. As Xtext uses AntLR 3 we need to leave the parent classloader empty to avoid confusions. After that we need to use reflection to call the right API.
As a fun fact we observed that the AntLR 4 Tool has two methods to process a grammar and both produce lexer and parser - but they are not equal. After fighting with that situation we found out that the method process is not the right choice as Codebuff got stuck with that the generated sources. ProcessGrammarsOnCommandLine produced the right result since it reorders the tokens by calling sortGrammarByTokenVocab and then called process.
Of course the generated classes are stored in a separated folder that is no source folder. Otherwise we would end up in compile errors in the project. ;-)
3. Compile lexer and parser
We cannot simply compile the lexer and parser like the rest of the code since AntLR 4 is not on the classpath. To achieve compiling we used the javax.tools.JavaCompiler directly. To use it we need to bring referenced classes into a special classloader. For this use-case the AntLR 4 jar is enough. After that we need to handle in the files to compile - that's it. Of course the compiled class files are stored in a separated folder as well. ;-)
4. Use Codebuff with the compiled classes without bringing it on the classpath
To achieve that we used the same trick as for AntLR 4 and downloaded Codebuff on demand once. So we ended up in two jars, AntLR 4 and Codebuff, a grammar and compiled lexer and parser. Now we need to combine all those things.
Codebuff does not really have an API to use it somewhere else then the commandline. Normally the Tool class needs a bunch of information including a destination file.
The formatter API in Xtext does not write to a file directly. It needs to set the formatted text as a string. Because of that the given approach does not work for use. We digged a bit in the code and yes there is a way that is slightly complicated and as you know we have to do everything through reflection ;-)
To explain it in a simple way we will just mention the steps without showing the ugly reflective code.
- We need to instantiate a
org.antlr.codebuff.misc.LangDescriptorthat holds all necessary information about the language. That includes the folder of the examples, a regex to identify examples, the compiled lexer and parser, the root rule of the grammar, the amount of spaces that make an indentation and the rule for comments. - We need to load all examples to invoke the train method that fills the matrix with token properties.
- We need to parse the document that we want to format.
- We need to instantiate the formatter and fill in the necessary information including the training result.
- We need to invoke the formatter to get a string back that represents the formatted document.
Sounds simple but we have to admit that it was pain. If Codebuff would have a more user friendly API, it would have been much simpler – we are planning to create a pullrequest to Codebuff to make it easier.
On Xtext side the story is simple – we need to bind a org.eclipse.xtext.ui.editor.formatting.IContentFormatterFactory to create our org.eclipse.jface.text.formatter.IContentFormatter that has only one method that gets the document that holds all necessary information and we can directly set the new formatted text.
The only tricky part that is left is classloading. We need to have Codebuff, AntLR4 and the compiled lexer and parser in a classloader. Of course a URLClassLoader solves the problem as we already downloaded the necessary jars and compiled the lexer and parser.
As a wrap up we can say that Codebuff creates a nice way to get rid of an old problem – but it's not perfect. For the future of Xtext it would be nice to have something like that included. Currently we are looking into alternative approaches and enhancements of the existing Codebuff codebase. Stay tuned.
Comments