
We are developing Modelix, a new browser-based language workbench with real-time collaboration support and with MPS in the backend. In this post you will learn what drove us to this project, what the main architectural building blocks are and what the current status is. Modelix is open source. We’re looking forward to your contributions.
Where we come from
The language engineering team at itemis Stuttgart has spent the last 10 years developing rich, multi-notation domain-specific languages for a variety of customers both in classical business domains as well as in engineering and healthcare. We’ve built a
- textual language for defining the dosage of medications,
- a Word look-alike language for specifying insurance rules,
- a whole range of extensions for the C programming language,
- functional languages for payroll and tax calculations,
- a box-and-line-style diagramming DSL for automotive interface specifications,
- a commercial tool for security risk analyses of technical systems,
- and a whole lot more.
These domain-specific languages all come with a type system, state-of-the-art IDE support and some also sport advanced analysis, such as model checking, SMT solving or dataflow analysis. They are used by dozens or hundreds of users each, in business-critical contexts, with customers all over the world.
Our Experience with Jetbrains MPS
What has enabled us to do all of this is MPS, a language workbench developed by Jetbrains as open source software that offers unique productivity for language development. The deciding characteristic is its projectional editor. That makes it different from all other practically usable language workbenches. MPS does not rely on parsing, it provides a unified architecture for textual, symbolic, and graphical notations, allowing seamless mixing of these styles.
In addition, again because MPS doesn’t rely on parsing, it provides robust support for language modularity and composition. One concrete benefit of this approach is that we were able to develop a functional base language. This can be embedded in any number of DSLs, avoiding the need to redevelop the basic abstractions for arithmetics, conditionals or primitive types. This provides a significant speedup when developing domain-specific languages and IDEs for our customers.
Over the years, we have also developed a wide range of MPS extensions, from a convenient way to specify nicely usable editors through a framework for developing in-IDE interpreters that enables zero-turnaround program execution and live programming to base languages for systems engineering and product line variability.
The Good and the Bad
We are revisiting this history in order to point out that our business relies on exploiting the capabilities of MPS to the fullest, including the capabilities of extending MPS itself by means of language extension – bootstrapping is really powerful. MPS is our tool of choice for helping our customers solve their problems using the unique benefits of language engineering.
However, nothing is perfect. There are a couple of shortcomings with MPS. As we expand the scope of what we and our customers do with MPS in terms of the size of the projects and the variety of skills of our language users, these shortcomings are increasingly becoming a problem. I will mention the three most important ones.
MPS needs to go web
The first shortcoming is that MPS is not on the web. Obviously there is a trend for all kinds of applications to move into the browser, with the backend running in the cloud. This is also true for development tools, although the trend is a bit slower there compared to run-of-the-mill applications – developers like their powerful machines, feature-packed IDEs and rich interactions with the tool.
But many of our end users, be they healthcare professionals, tax experts or systems engineers, are not software developers. Their ecosystem increasingly moves into the web, and installing a 500 MB IDE on their desktop computer is increasingly becoming hard to explain.
Some of our users also use the tool only occasionally, for example, to perform reviews. For these users, installing an IDE on their computers is even less appealing.
Finally, relying on the browser opens up the possibility of integrating users on the public internet or along a larger supply chain. Here it is out of the question to distribute, install and regularly update an IDE.
So: we need to move to the web. It’s inevitable.
Realtime Collaboration
The second aspect is our users’ expectation regarding how they collaborate. There are two opposite trends. In many engineering contexts, users move away from proprietary repositories, adopting technologies that are common in software development, namely file-based versioning with git.
On the other hand, many people got to appreciate to real-time collaboration through Google docs, where a group of users can simultaneously edit a document; they can see everybody else’s edits, and conflicts are resolved immediately. From this experience, and because many aspects such as merging are really painful to do with git, users want to see real-time collaboration also for modeling tools.
The analogy with collaborative document editing doesn’t completely hold though, because users do want a degree of isolation: you don’t want your model/program to fail a test or an analysis because another user just changed it under your fingers.
Summing up, MPS’ sole reliance on files and git is perceived as a problem in many contexts; some form of real-time interactive collaboration is needed, enhanced with a mechanism for temporary isolation and some of git’s features, but in a more user-friendly package.
Liveness
A third concern is liveness. MPS has historically relied on the classical edit-compile-run cycle, where “compile” means generation of executable artifacts such as Java or C code from higher level models. However, often influenced by Excel, many users expect richer and more immediate interactions with the model, blurring the boundary between editing and execution or analysis.
For example, test cases should run automatically whenever the model or the test specification changes, or a performance analysis should update its result as the engineer updates the resource constraints in the model.
While we have built several DSLs that provide an approximation of such features – for example, by integrating the KernelF interpreter into the IDE, running an discrete event simulation on every change of the input model, or performing an incremental model transformation using Shadow Models whenever the source changes – the architectural support of MPS for this style of DSLs is limited.
Simplify!
A final problem is MPS’ perceived complexity and IDE-ness. Professional developers and some of our expert end users are ok with a tool that has multiple views, tabbed editors, dozens of buttons in the toolbar and literally 50 entries in a context menu. However, lots of our language users are completely overwhelmed by this amount of options.
While MPS can be customized regarding the available views and buttons and menu entries, its fundamental nature as an IDE remains. Again, this is a plus for some of our users, those that need (and maybe are already familiar with) IDEs. But the majority of our end users, the tax specialists, healthcare professionals or insurance product developers, prefer a less complex, more task-oriented UI.
A vision for the future
A while ago we wrote a vision whitepaper that outlines where we think a language workbench of the future should go. I’ll summarize it here briefly, and then discuss our concrete steps towards this vision in the next section.
Tool Architecture
At the core of the kind of industrial-scale modeling tools the vision paper describes is a distributed database that stores graphs. These graphs represent both the front-end models edited by users, as well as intermediate models or results of analyses that are computed by the tool itself.
For every edit operation the user performs via the browser on whatever model she edits, the editor sends a change event to the repository that updates the master model. Transformation services, directly connected to the repository, listen to particular kinds of change events, and when they see one, they incrementally update the result models they are responsible for. This update might involve the execution of a test case (updating the result data), rerunning of a quick performance analysis or something as mundane as the type checks for the user-facing model. The updates to the result models are then transferred back to the client side editor, if the client has subscribed to the particular model.
Services might also execute longer-running analyses, such as model checking a complex state machine or generating a whole bunch of Java. At the core, however, the platform is designed to support this incremental, real-time update of computed data to enable liveness.
Those deltas are also the basis for deconflicing concurrent edits to the same nodes, which in turn is the basis for Google Doc-style real-time collaboration.
A set of Editors
Of course not all editors will be delta-oriented, and there will also be other clients that just want to work with snapshots of models – user-created or computed. For this purpose, the tool will provide REST APIs for reading and writing complete models via JSON-based bulk data. A particularly important example of such a client is a CI server that grabs models and then runs maybe a code generator and a subsequent compiler to create the artifacts ultimately required by the users.
Usable and powerful editors are certainly crucial for this vision, not least because they are the primary user-facing components of the system. However, for this same reason, editors will exhibit the largest variety: for simple languages, we want simple editors with very little if any chrome; more sophisticated systems perhaps need more powerful editors with quick fixes, refactorings and a whole array of buttons and menus around it. While out-of-the-box default editors are needed, we expect an ecosystem of different styles of editors to be developed over time.
The system should also support some of the standard functionalities of enterprise systems, such as permission checking, auditing and payment.
Language Development
The meta level, where language engineers develop the languages, would be nice to also have available in the web. However, for the time being, it is acceptable to continue this work in a “fat” IDE: there are comparatively few people who do this work, and they are developers. From the perspective of language engineering – the overall set of language features, the range of notations as well as the support for language modularity should be similar to (or potentially better than) MPS.
What we are doing about it: Modelix
As a concrete first step in realizing the vision I have outlined above, we have started the Modelix project. It is open source software and you can find it at modelix.org. As a cornerstone it relies on running a set of MPS instances on the server. These provide the language services available in MPS, including scoping and code completion, type checking or code generation.
Because we rely on MPS, language development can continue in MPS and existing MPS languages can be used immediately in modelix. To support web-based editing, modelix “forwards” the MPS editors to the browser; again, any notation that works in MPS will also work in modelix. To support scaling of server-side resources and to allow for failover if an MPS instance crashes, the models are stored in a shared database. This shared database is also the key for collaborative real-time editing.
As a side effect of this architecture, a user of a regular client-side MPS can connect to that database as well, getting the benefits of real-time collaboration even without the web-based interface.
Modelix can either be run locally via Docker, or in the cloud via Kubernetes. We have also implemented a gradle plugin for accessing the shared database from a CI server. The following illustration shows the main building blocks.
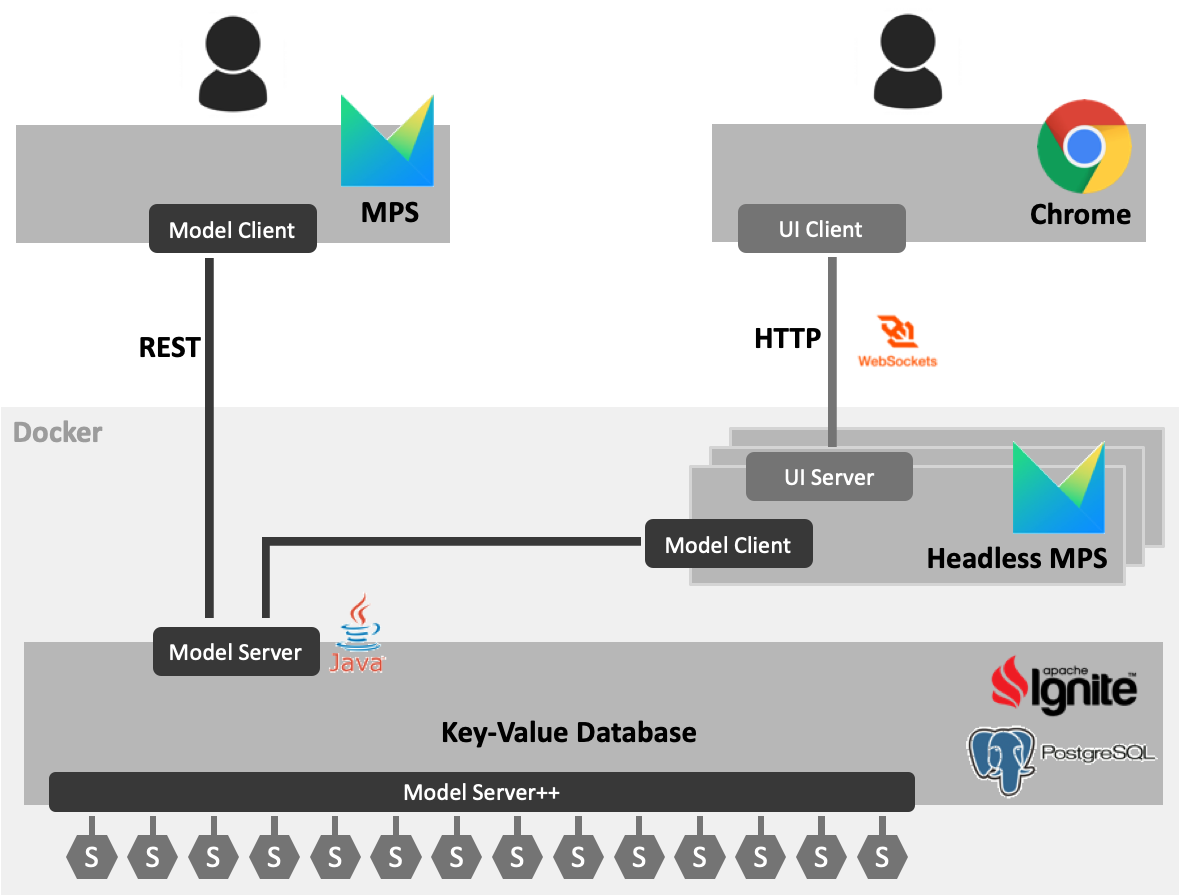
On a parallel track, the development of an API for accessing the models in the shared database has started. This will be the basis for developing services which analyse, execute or otherwise modify models without going through MPS. In addition, this will be the basis for the REST-based bulk model APIs mentioned above.
Where are we
Modelix is currently a prototype that demonstrates the feasibility of the idea: it wasn’t obvious that running MPS in the cloud, managed by Kubernetes, and forwarding the MPS-rendered editor into the browser would be feasible. Turns out it is, at least as a pragmatic first step.
We are currently in the process of setting up a modelix instance in the cloud, so if you want to play with it, you can get in touch and we’ll give you access.
We have also started talking to “friends and family” to try and make sure Modelix becomes a true collaborative open source project, and not something effectively owned by itemis Stuttgart and the main developer Sascha Lißon. So if you are interested in the future of language workbenches, get in touch and then get involved.
Comments