
Insurance products are complicated. They involve sophisticated math and lots of interacting rules. They exhibit significant variability between different markets. They change over time, for example, driven by changes in law or updated risk assessments from the company. In addition, once consumers sign an insurance contract, they must not be affected by changes to that product (or at least they must not be worse off), which means that “old” contracts must continue to be executed with the “old” logic.
Since the insurance domain is very mature, insurance products are available for almost everything; it is getting harder for insurance companies like Zurich to innovate and distinguish themselves from other insurance providers in ways other than beating their competitors’ prices. But even this is difficult: you still need to know if a potential change to an insurance product undercuts your margin. On the other hand those products, along with the risk assessment, are the core assets of an insurance company – they are central to their success as a business.
At our customer Zurich, those products are created and maintained by a small group of people called product modelers. Zurich’s team is a mix of mathematicians and MBAs. The products are specified using lengthy requirements documents written in Word. They try to capture all the details and corner cases, but because of the intricacies of the products, it is very hard to describe them consistently and unambiguously using what is basically a writing tool (Word). Consequently, the overall product development process is slow and error-prone, something that turned out to be a significant limitation to our customer’s business agility and competitiveness.
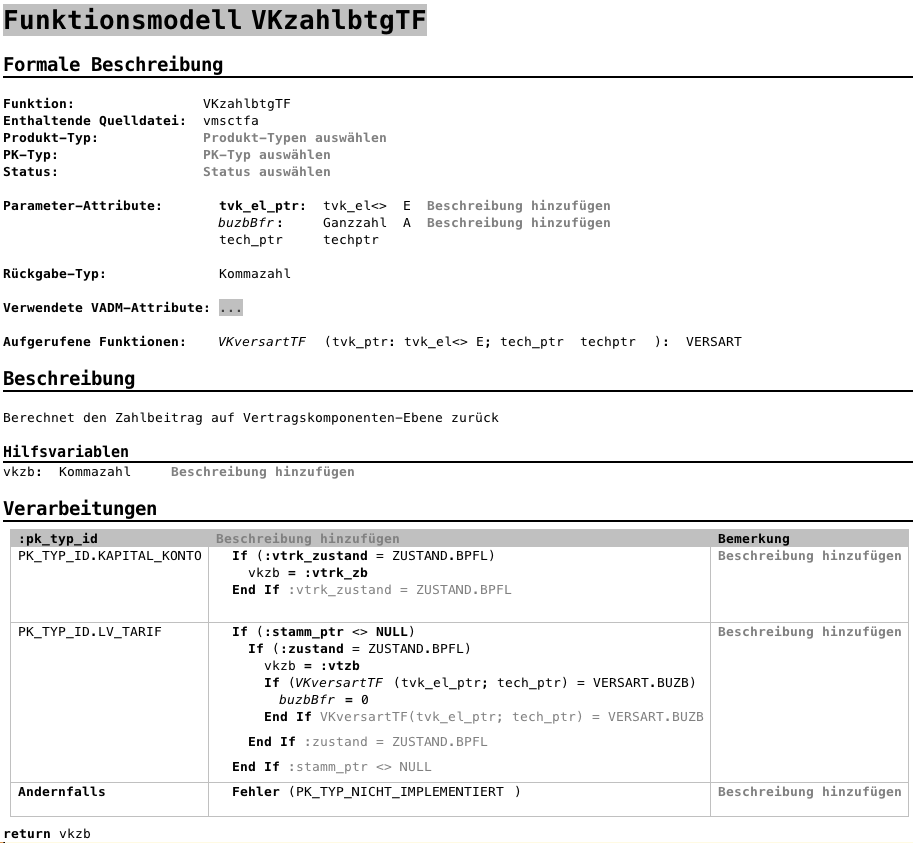
In an attempt to improve this situation, Zurich enforced a rigid structure on these documents. The screenshot below shows an example. While this makes them look almost like a program, relying on specific words and notations, Word is not aware of those and thus does not provide any support, not even the most basic consistency checks. For a programmer, the equivalent would be to write software in text editor without ever compiling it before releasing it into production.

Eventually, the requirements documents are handed over to an external IT service provider. Their task is to precisely understand all aspects of the product specification and to implement them faithfully in C for execution on a mainframe. If there is an update to the product they have to understand the change and its implications. Over time the software engineers have to become insurance experts – without having the necessary background.
Once the software is implemented it must be validated against the specification. This involves the product modelers again. If they discover undesired behavior they must understand the reasons, often requiring them to dig into code they have never seen, are not supposed to see, and likely will not understand. The product modelers are expected to become software engineers -- without having the necessary background.
This whole process is time-consuming and error prone. It severely hindered Zurich’s ability to innovate. We have seen similar challenges at other insurance/finance customers; our customer is not alone with this predicament. Concrete examples include social security payments or tax calculations.
So what did we do?
Essentially we built a dedicated tool that is aware of Zurich’s established “language”: it knows about the domain concepts and assists the insurance product modelers in their work. A screenshot is below. The tool supports the modeler in ways similar to a software developer’s IDE: reporting errors, issuing warnings, code completion, navigation to other rules, but also refactorings. At the same time, and in contrast to IDEs, it embodies the established abstractions and notations from our customer’s insurance product domain, including tables or mathematical symbols. In the case of this particular customer this was comparably easy, because they already went a long way in formalising those. The resulting tool behaves like a mix of a form based application (providing structure), a text editor (supplying flexibility and expressiveness), a formula editor (for math notations) and a spreadsheet (for the tables).
The captured rules are now formal enough to make them suitable for generating the implementation in C. It remains the task of the software engineers to integrate those artifacts into the runtime system, make the system scale, monitor its operation and deal with security.
Did it work?
The tool has been successfully released to production and is now used by the product definition team at Zurich. Hundreds of rules are being described this way, and the implementation is automatically generated. Introducing the DSL and the supporting tool streamlined the collaboration between product modelers and programmers significantly: each group can focus on their particular strengths. The overall efficiency of product development has been increased, and the error rate reduced.
The tool is built on top of MPS, the language workbench we have been using successfully for the last few years to build DSLs for non-programmers. However, as more and more business processes move to the web, a similar tool platform must be available in the browser. It should also be optimized for business users in terms of their UI complexity and collaboration processes.
Comments