
If you are dealing with the term requirements coverage in the context of systems or software development you might discover the following ambivalence:
This article is part 3 of our series about “requirements traceability”.
You should also pay attention to:
On one hand, requirements coverage comes with room for interpretation, because it is not well-defined. On the other hand, several well-defined process standards and maturity models demand that coverage has to be measured, especially in safety-critical developments. In this post, I am going to report on some experiences we made when we were confronted with that ambivalence and on how we approached an “adjustable definition” of the term coverage.
Existing definitions of “requirements coverage”
Let’s have a look at three different sources for a definition of the term requirements coverage. As we will see, according to all the sources, requirements coverage addresses the direct relationship between requirements and test cases
A Google Search shows several definitions of the term, but they are not universal. The majority of these definitions are related to commercial requirement management tools and thus they are tool-specific. Anyhow, they have one thing in common: It seems that they consider a requirement as being covered, if at least one test case is assigned to it.
Wikipedia (at least the English and German one) does not provide any definition of requirements coverage. However, it defines code coverage as a measure to describe “the degree to which source code is executed when a test suite runs”.
Automotive SPICE is a standard to assess the maturity of the process for the development of control modules in the automotive industry. The A-SPICE Process Assessment Model (PAM) utilizes the V-Model. When it comes to verifying development artifacts of a given type the PAM demands that “the selection of test cases shall have sufficient coverage”.
Real-life encounters of requirements coverage
The following picture roughly illustrates a development process according to the V-Model. I am going to use it to report on our experiences.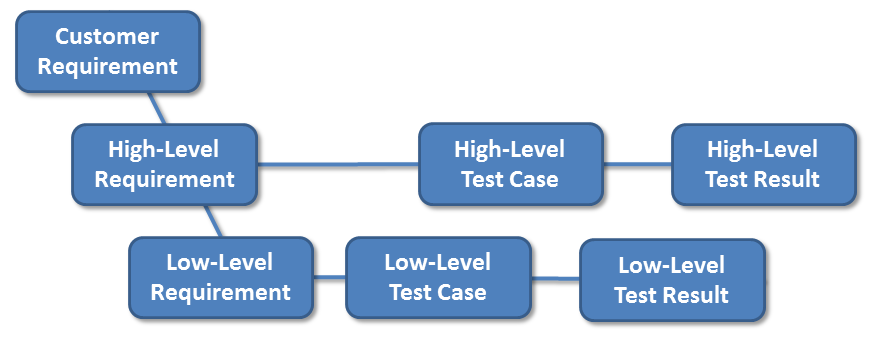 (Customer test cases are customer’s responsibility and therefore not considered.)
(Customer test cases are customer’s responsibility and therefore not considered.)
In a specific project, the customer demanded regular progress reports based on their customer requirements. They wanted to know how many of them are analyzed, implemented, and covered.
The terms analyzed, implemented, and covered were defined based on coverage metrics:
- analyzed: covered by high-level requirements, i.e. a customer requirement must have at least one high-level requirement assigned.
- implemented: deeply covered by low-level requirements, i.e. analyzed + all derived high-level requirements are covered by low-level requirements.
- covered: deeply covered by test cases, i.e. implemented + all derived requirements are covered by test cases.
Let me illustrate this by means of some images showing development artifacts and their traceability links:
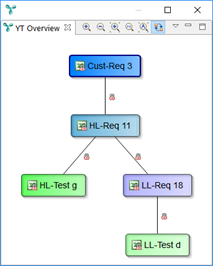
Customer requirement Cust-Req 3 is covered: high-level requirement HL-Req 11 and low-level requirement LL-Req 18 are derived, both have an adequate test case assigned (HL-Test g and LL-Test d, resp.).
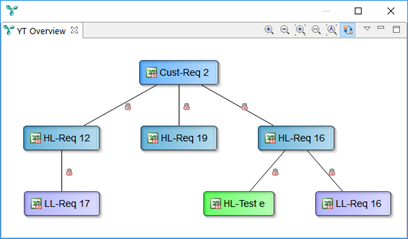
Customer requirement Cust-Req 2 is analyzed. It is not considered implemented, because HL-Req 19 lacks a low-level requirement.
So, what did we learn from this project ?
The definition of Requirement Coverage given above as “direct relationship between requirements and test cases” is not sufficient.
- Coverage is not only important on the same level of the V, but also on the left leg of the V.
- We have to distinguish between
- direct coverage as meant by the above definition and
- deep or transient coverage which requires to trace requirements not only directly or horizontally on the same level, i.e. from the left leg of the V to right leg, but also in vertical direction between levels, i.e. from a higher level to a lower level within the left leg of the V).
Our definition of coverage
Summing it up, we define coverage as follows:
A development artifact (requirement, test case, test result, code, etc.) is “covered by a given type of artifacts (target type)”, if
- it can be traced to at least one artifact of the target type, and
- this definition applies recursively for all artifacts which are derived from the source artifact and which – with regards to the process definition in the V-Model – are potential ancestors of artifacts of the given target type.
Based on this definition, we can state the following (please refer to above images):
- “Cust-Req 3 is covered by low-level tests.”
- “Cust-Req 2 is covered by high-level requirements.”
- “Cust-Req 2 is not covered by low-level requirements.”
What I didn’t mention...
This post is a simplified summary of several project experiences. I did fade out:
- The V has usually more levels.
- This post did not consider test results. Taking the results into account, we can additionally analyze whether a requirement is verified.
- We also need to certain consider properties of development artifacts. Examples:
- A low-level requirement which is not yet “approved” must not be considered during coverage analysis.
- Sometimes requirements can be flagged to be considered as being “covered by …” – even if they are not linked to anything. This might happen e.g. due to the order of the project lead.
- In some projects, the derivation of requirements is allowed on the same level, e.g. a high-level requirement can have another high-level requirement as its ancestor. To make it really complicated: We sometimes have to distinguish between split and derivated requirements:
- If the ancestor requirement is “split” into several requirements of the same level, the ancestor is to be considered covered if all its descendants are covered. That is, the coverage has been “delegated” to the sections resulting from the partitioning.
- If the ancestor has only “derived” requirements on the same level, both ancestor and descendants need to be linked directly or indirectly to artifacts of lower levels.
- Even within the same project, the variety of roles and tasks made it necessary to support variations of the definition coverage. We encountered homonyms such as “high-level requirements are covered” which means different things depending on whether the person who stated this was responsible for high-level tests or low-level requirements.
Our approach: Establish tool-supported traceability
Here’s another quote from the Automotive Spice PAM: “Bidirectional traceability supports coverage, consistency and impact analysis.”
So, if you want (or need) to measure your requirements coverage, you need to establish traceability.
But how can you do that efficiently? Several guides recommend to maintain a traceability matrix as a base solution. This looks feasible on first view, however, it does not scale. I cannot even imagine how a matrix with n dimensions (one for each layer of the V) and more than thousand rows and columns would look like, not to mention having to maintain it.
Instead, what you need is a tool for your traceability management. Good traceability tools
- recognize artifacts easily (in order to link them readily),
- support the user heavily in creating links, e.g. by efficient search and selection mechanisms to get down to the artifacts that should be linked,
- ideally derive links based on similarities,
- extract links that you have already maintained in other tools.
But the most important thing is:
- Evaluation of trace data (artifacts and their links) must be as easy as possible.
Look for a tool that provides the following:
- Static reporting: Various reports in several formats should be provided. It should be possible both to create ad-hoc reports and to support regular and automatic reporting in a continuous approach.
- Dynamic queries: The tool should provide means to create queries which are adjustable by the user. The query language should be human readable, of course. It should comprise high-level and expressive features to traverse the graph of artifacts and links. That is, the user should be able to write such queries without even knowing what “graph theory” is.
- Data export: The tool should provide means to export the trace data into other formats for further analysis, e.g. into an Excel sheet or a database. This holds true both for raw and pre-aggregated trace data.
Requirements coverage analysis with YAKINDU Traceability

The above chapter listed some criteria for the evaluation of traceability tools. Our tool recommendation is YAKINDU Traceability. The following screenshot shows an example of YAKINDU Traceability's analysis perspective. At the top, it shows a dynamic query and query result below.

The result is a Requirements Traceability Matrix: As opposed to a classical two-dimensional matrix, YAKINDU Traceability shows a list of trace chains. If any artifacts are not covered these trace chains contain gaps – both in forward and in backward direction. This representation scales and can be analyzed easily both by humans and using further queries. For example, let’s focus on the three rows for Cust-Req 2: The first row means that this requirement is linked to HL-Req 12 which in turn is linked to LL-Req 17. The second row is analogous to the first one. The third row, however, is not completely filled. This means that Cust-Req 2 is not covered by low-level requirements. For illustration purposes, the YAKINDU Traceability Overview is also included. It displays the trace graph showing artifacts linked to Cust-Req 2.

Please note that in this post we’re just using a small set of sample test data. In order to create the screenshots I have configured YAKINDU Traceability to recognize all requirements and test cases from the very same Excel sheet shown below.

Even for this tiny amount of data, imagine how a “conventional” traceability matrix would look like and how hard it would be to find the relevant data in that matrix.
If you want to learn more about YAKINDU Traceability and its features check our blog.
Comments