
Performance benchmarking for Domain-specific Languages (DSLs) is rarely done at all. Customers usually do not want to edit and manage huge input models as the given DSL should provide a proper abstraction. Nevertheless, we have seen large performance differences or degradation during the evolution of DSL implementations, e.g., due to simply adding new features, like new domain-specific validations.
Hence, gaining insights into the performance characteristics with a quantitative evaluation benchmark for the implementation of your Xtext-based DSL can be beneficial. This might help to detect performance degradation while implementing additional features or while trying to scale for larger input models.
This article applies JVM-based micro-benchmarking to the parser, the interpreter, and the validation for a simple Xtext-based DSL. On the technical side, all benchmarks were performed with JVM pre-warming and multiple runs to automatically eliminate noise due to JIT compilation, garbage collection or undesired heap allocation patterns. We do not want to get our hands dirty doing these tedious tasks on our own so we utilize JMH. This is a Java harness for building, running, and analyzing time-based benchmarks written in Java and other languages targeting the JVM.
Build a Math Expression Language with Xtext
Simple mathematical expressions, e.g., 1 + 2 + 3 * 0 should be correctly parsed, interpreted, and validated. The following implementation is a slightly adapted version of the simple arithmetic expression DSL, that is shipped with Xtext already:
grammar de.itemis.jmhmathexample.MathDSL with org.eclipse.xtext.common.Terminals
import "http://www.eclipse.org/emf/2002/Ecore" as ecore
generate mathDSL "http://www.itemis.de/jmhmathexample/MathDSL"
Math:
expression=Expression;
Expression:
Addition;
Addition returns Expression:
Multiplication (({Plus.left=current} '+' | {Minus.left=current} '-') right=Multiplication)*;
Multiplication returns Expression:
PrimaryExpression (({Multi.left=current} '*' | {Div.left=current} '/') right=PrimaryExpression)*;
PrimaryExpression returns Expression:
'(' Expression ')' |
{NumberLiteral} value=NUMBER;
terminal NUMBER returns ecore::EBigDecimal:
('0'..'9')* ('.' ('0'..'9')+)?;
@Override
terminal INT returns ecore::EInt:
'this one has been deactivated';
This generates the following meta-model:
The full implementation can be found in this Github repository.
Build the JMH-based Benchmark
The authors of JMH recommend to use Maven to set up a standalone project that depends on the jar files of your application. This is done in the de.itemis.jmhmathexample.benchmark.jmh project.
Using a standalone project is preferred to ensure that the benchmarks are correctly initialized and produce reliable results. With enabling the JMH annotation- and bytecode-processors to generate the synthetic benchmark code via Maven, no additional work by the user is required.
A quite compact tutorial for JMH can be found here. Additionally, you may want to add more specific profilers to inspect e.g., class loading, garbage collection, memory, or threading characteristics.
With the prerequisites introduced above we are finally able to write the benchmarks itself.
Benchmark the Parsing Process
We start right away with a benchmark of the parsing process. How long does it take to parse arbitrary large strings into an Ecore model instance?
To simplify the actual benchmarking code a bit we introduce the following abstract base class for initializing all the required bits and pieces:
@BenchmarkMode(Mode.SingleShotTime)
abstract public class AbstractDSLBenchmark {
@State(Scope.Benchmark)
abstract public static class AbstractBenchmarkState {
protected Injector injector = new MathDSLStandaloneSetup().createInjectorAndDoEMFRegistration();
protected XtextResourceSet resourceSet = injector.getInstance(XtextResourceSet.class);
protected IResourceValidator resourceValidator = injector.getInstance(ResourceValidatorImpl.class);
protected Resource resource = resourceSet.createResource(URI.createURI("dummy:/example.math"));
// Specify your own input model sizes here:
@Param({ "100", "1000", "10000" })
public int size;
private java.util.Map<epackage, java.lang.object=""> validators = new HashMap<>();
public AbstractBenchmarkState() {
if (null == injector)
throw new RuntimeException("injector is null!");
if (null == resource)
throw new RuntimeException("resource is null!");
if (null == resourceValidator)
throw new RuntimeException("resourceValidator is null!");
if (null == resourceSet)
throw new RuntimeException("resourceSet is null!");
resourceSet.addLoadOption(XtextResource.OPTION_RESOLVE_ALL, Boolean.TRUE);
}
public void disableValidators() {
validators.putAll(EValidator.Registry.INSTANCE);
EValidator.Registry.INSTANCE.clear();
}
public void enableValidators() {
EValidator.Registry.INSTANCE.putAll(validators);
}
}
}
The variable size is now used to generate the actual parser input and run the benchmark calling parse:
public class MathDSLBenchmark extends AbstractDSLBenchmark {
public static class ParserBenchmarkState extends AbstractBenchmarkState {
private MathDSLGenerator generator = new MathDSLGenerator();
public String inputString;
@Setup
public void setup() {
inputString = generator.generate(size, GenerationStrategy.WITHOUT_DIV);
disableValidators();
}
public Math parse(String input) {
InputStream in = new ByteArrayInputStream(input.getBytes());
try {
resource.load(in, resourceSet.getLoadOptions());
} catch (IOException e) {
e.printStackTrace();
}
return (Math) resource.getContents().get(0);
}
}
@Benchmark
public void benchmarkParse(ParserBenchmarkState s, Blackhole sink) {
sink.consume(s.parse(s.inputString));
}
}
Benchmark the Interpretation Process
We follow this pattern for benchmarking the interpretation process:
public static class InterpreterBenchmarkState extends ParserBenchmarkState {
private Calculator calc = new Calculator();
public Expression exp;
@Setup
public void setup() {
super.setup();
exp = parse(inputString).getExpression();
}
public BigDecimal interpret(Expression exp) {
return calc.evaluate(exp);
}
}
@Benchmark
public void benchmarkInterpreter(InterpreterBenchmarkState s, Blackhole sink) {
sink.consume(s.interpret(s.exp));
}
Please note: for interpreting such large input models, the standard recursive interpreter shipped with the simple arithmetic expression DSL is not suitable, as it will fail with a StackOverflowException. Hence, it was rewritten using an iterative, stack-based approach.
Benchmark the Validation Process
And finally, the validation can be benchmarked:
public static class ValidatorBenchmarkState extends ParserBenchmarkState {
public Expression exp;
@Setup
public void setup() {
super.setup();
exp = parse(inputString).getExpression();
enableValidators();
}
public List validate() {
return resourceValidator.validate(resource, CheckMode.ALL, CancelIndicator.NullImpl);
}
}
@Benchmark
public void benchmarkValidator(ValidatorBenchmarkState s, Blackhole sink) {
sink.consume(s.validate());
}
Run the JMH-based Benchmark
Clone the provided Github repository and follow these steps to run the JMH-based benchmark with Maven:
- Make sure a recent Java (>1.8), ant, and Maven is installed.
- Build the standalone Jar for
de.itemis.jmhmathexamplewith running ant there (seeexport.xml). - Build local Maven repo and deploy the Jar generated in step 2 into it:
mvn deploy:deploy-file -Dfile=./bin/MathDSL.jar -DgroupId=de.itemis -DartifactId=de.itemis.jmhmathexample -Dversion=1.0 -Dpackaging=jar -Durl=file:./maven-repository/ -DrepositoryId=maven-repository -DupdateReleaseInfo=true. - Build the JMH augmented standalone Jar for
de.itemis.jmhmathexample.benchmark.jmh:mvn clean install. - Run the benchmark and generate the json result file:
java -jar target/benchmarks.jar -rf json.
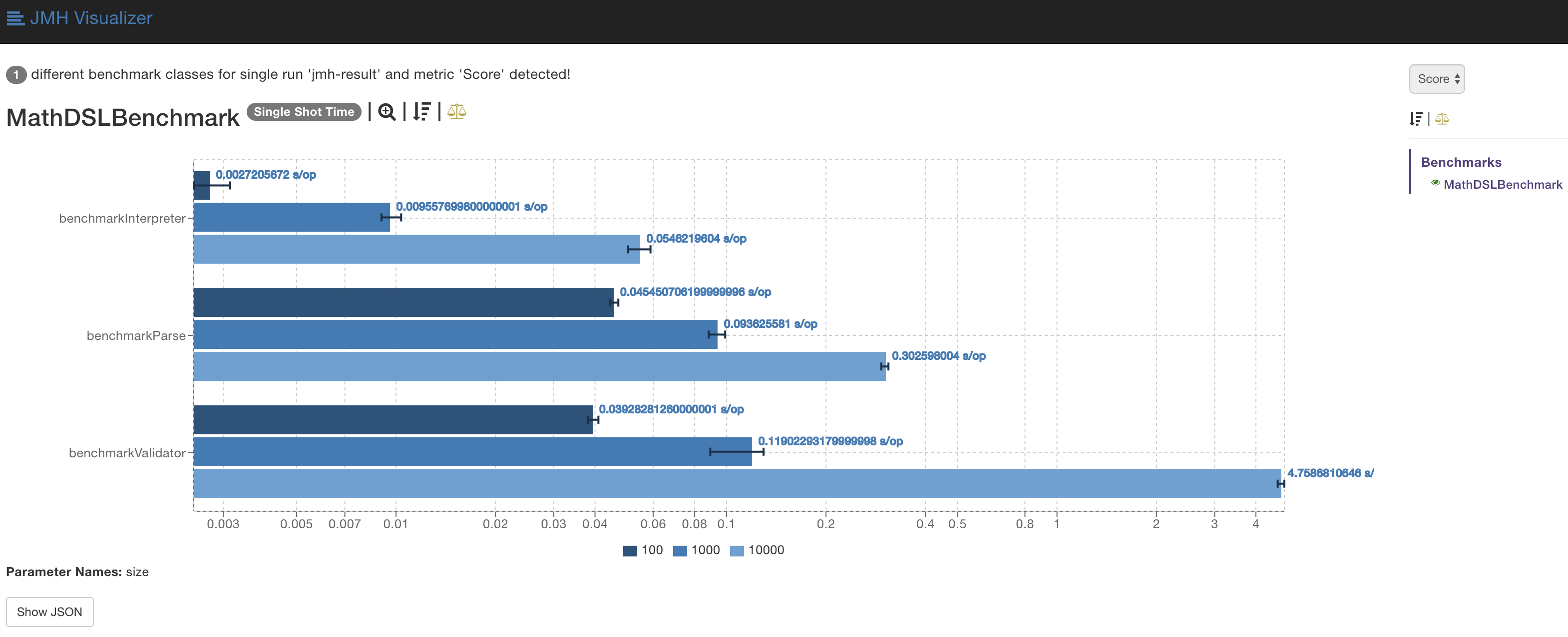
Visualize the Results
The JMH Visualizer prints nicely formatted graphs of the resulting json file. Even multiple files from different runs can be imported and compared side-by-side. This makes regression testing a lot easier, as you are able to spot performance losses in a second.
Limitations of JVM Micro-benchmarking
As already mentioned above, JMH-based benchmarks automatically perform JVM pre-warming and multiple runs to automatically eliminate noise due to JIT compilation, garbage collection or undesired heap allocation patterns.
There are many mechanisms in the JVM which are transparent to the programmer, for instance, automatic memory management, dynamic compilation and adaptive optimization. Importantly, these mechanisms are triggered implicitly by the code being executed, and the programmer has little or no control over them:
- JIT compilation: The HotSpot compiler continually analyzes the program performance for parts of the program executed frequently and compiles those parts down to machine code. Any part of the code can potentially be chosen for compilation at any point during the runtime, and this decision may be taken in the midst of running a benchmark, yielding an inaccurate measurement. Also, portions of the program are periodically recompiled but can also be de-optimized based on the JVM runtime information. Hence, during the runtime of the program, the same code might exhibit very different performance characteristics.
- Classloading: Since the JVM, unlike a typical compiler, has global program information available, it can apply non-local optimizations. This means that a method may be optimized based on the information in some seemingly unrelated method. One such example is inline caching, where the JVM can inline polymorphic method calls. Since not all the classes loaded in the complete application are loaded in a benchmark, many of the callsites in a benchmark can and will be optimized, thus yielding an inaccurate running time measurement. As a result, seemingly unrelated code can have a big impact on performance of the code being benchmarked.
- Automatic memory management: The benchmark is simply a piece of code running and measuring the running time of some other piece of code. As such, it may inadvertently leave the memory heap in a state which affects subsequent allocations or trigger a garbage collection cycle, each of which changes the observed performance of the code being tested. In a real-world application, the state of the heap is unpredictable, and in general different heap states and allocation patterns tend to give very different performance results. There are other non-JVM considerations to take into account as well. Specific processors, cache and memory sizes may show a very different performance for the same benchmark. On a single processor system, concurrently running applications or operating system events can cause a degradation in performance. Different Java Runtime Environment versions may yield entirely different results. These effects do not cause a linear degradation in performance. However, decreasing the memory size twice may cause the benchmark to run a hundred times slower. Additionally, performance of some code is not some absolute scalar value denoting how fast the code is. Rather, it is some function which maps the inputs and the runtime conditions to a running time. This function is impossible to reproduce analytically.
Benchmark conditions and inputs are hard to reproduce. Performance measurement introduces observer bias and runtime behavior is in general non-deterministic. With that, performance metrics inherently give an incomplete picture about the performance characteristics. With that being said, this benchmark portrays neither the real-world behavior of Xtext-based DSLs, nor does it result in a precise, reproducible performance measurement. Still, the benchmarking of the individual features (parsing, interpreting, validating) is important because it gives insights about the performance characteristics in some particular conditions (e.g., varying input model sizes). This information might not be complete, but it captures some characteristics your customers might be interested in.
Summary
In this article we applied JVM-based micro-benchmarking to the parser, the interpreter, and the validation of a simple math expression language based on Xtext.
Gaining insights into the performance characteristics of your Xtext-based DSL can be beneficial. It helps to detect performance degradation while implementing additional features or while trying to scale for larger input models.
Feel free to contact me or itemis for more in-depth information about Xtext and language engineering in general.
Comments