
Mit diesem Slogan bewirbt das Unternehmen Exasol sein gleichnamiges Datenbank-Management-System (DBMS) und bezieht sich dabei vor allem auf den TPC-H (Transaction Processing Performance Council)-Benchmark.
Der TPC-H-Benchmark testet dabei vor allem die Leistungsfähigkeit von Datenbanken im “Decision Support Bereich”.
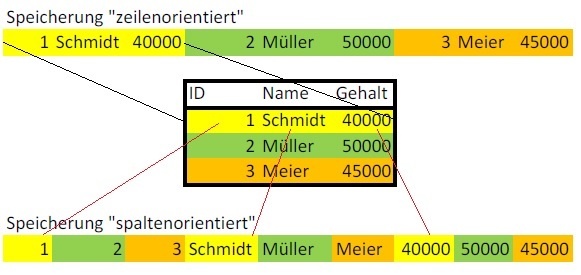
Bei der Exasol handelt es sich um eine spaltenorientierte “In Memory”-Datenbank, die vor allem für “Big Data”-Problemstellungen gedacht ist.
Ergänzend zu Standard-ANSI-SQL stehen dem Entwickler mit Java, Lua, Python und R vier Programmiersprachen zur Verfügung, in denen er eigene Funktionen (“User Defined Functions” oder UDF) und Scripte in der Datenbank implementieren kann.
Neben einer guten Performance und Skalierbarkeit verspricht Exasol vor allem, dass sich das Datenbank-Management-System selbst “optimiert”. Das bedeutet, dass es nicht notwendig sein soll, Indizes anzulegen, dem Optimizer mit “Hints” auf die Sprünge zu helfen oder andere Tuning-Maßnahmen vorzunehmen.
Anwendungsszenario für die Exasol
In einem Kundenprojekt hatten wir die Gelegenheit, die Exasol zu verwenden und auszuprobieren. Dabei wurden in Vorprozessen zunächst Informationen aus unterschiedlichsten Quellen validiert, strukturiert und standardisiert – in Summe mehrere Milliarden Datensätze.
Die Aufgabe des eigentlichen “Kernprozesses” war es dann, diese Daten anhand definierter Merkmale auf Gruppen zu verteilen, innerhalb dieser Gruppen “ähnliche” Datensätze zusammenzuführen bzw. miteinander zu verknüpfen und am Ende den “besten” Datensatz aus einer Menge von verknüpften Datensätzen auszuwählen.
Technische Umsetzung
Aus den fachlichen Anforderungen ergaben sich vor allem folgende Herausforderungen, mit denen das DBMS effizient umgehen können sollte:
- Bilden und Filtern von großen Cross-Joins über alle Datensätze innerhalb der Gruppen, um alle Datensätze innerhalb einer Gruppe miteinander vergleichen zu können
- Ausführen von “Fenster-Funktionen” auf großen Ergebnismengen
- Ausführen von UDF für eine Vielzahl von Aggregaten
Ein wesentliches Projektziel war es, die Laufzeit des Kernprozesses (aktuell 2-3 Wochen) deutlich zu senken (im Idealfall auf unter einen Tag). Das Mittel der Wahl, um in der Exasol große Datenmengen möglichst schnell und effizient zu verarbeiten, miteinander zu vergleichen, zu filtern und zu aggregieren, ist die Verwendung von SQL-Abfragen. Um die dabei häufig auftretenden Nachteile (aufwändige Wartung, schlechtere Testbarkeit, kein Debugging) einzugrenzen, integrierten wir das Anlegen von sämtlichen Views und Funktionen vollständig in den Build- und Deployment-Prozess, so dass ausschließlich im git-Repository abgelegte Artefakte dauerhaft in das System gelangten. Die einzelnen Views wurden dabei in möglichst kleine Schritte zerlegt, so dass an entsprechenden Stellen Zwischenergebnisse ausgewertet werden konnten.
Java-UDF sind übrigens im Gegensatz zu SQL-Abfragen deutlich langsamer. Allerdings lassen sich damit aber auch deutlich komplexere Funktionen abbilden und diese dann auch mit Hilfe eines selbstentwickelten Mocks Unit-testen.
Stärken und Schwächen der Exasol
Das Testsystem (und das spätere Produktivsystem) bestand aus einem Cluster aus mehreren Knoten und in Summe einem Terabyte Arbeitsspeicher. Für unseren Anwendungsfall konnte das darunterliegende System überzeugen – insbesondere beim Bilden und Filtern der Cross-Joins sowie bei der Verteilung von UDF-Aufrufen über den gesamten Cluster.
Die klassischen Nachteile einer spaltenorientierten Datenbank z.B. bei INSERTs waren zwar bemerkbar. Da die entsprechenden Prozesse aber im File getriebenen Batch-Betrieb laufen und daher nicht so zeitkritisch sind, waren diese Nachteile zu vernachlässigen. Für klassische OLTP (Online-Transaction-Processing)- Anwendungen ist die Exasol sicher nicht die erste Wahl.
Im Projektalltag hatten wir zwei Situationen, in denen sich das DBMS hinsichtlich der Laufzeit nicht so verhielt, wie wir es erwartet hätten. Beide konnten aber durch reines Umstellen der Abfragen umgangen werden.
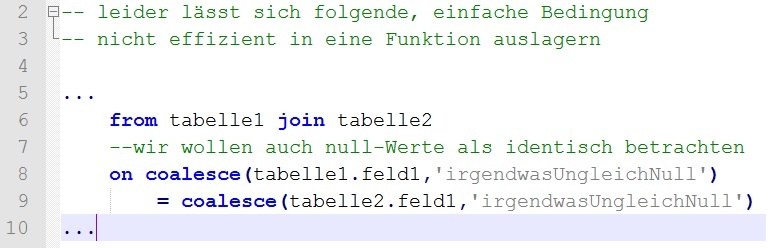
Davon betroffen war zum einen die Verwendung von selbstgeschrieben (einfachen) Funktionen in Join-Bedingungen, die anscheinend nicht analysiert wurden. Erst die Ausformulierung der Bedingung direkt in dem Join führte zu einer deutlichen Verbesserung.
Zum anderen stieg bei der Verwendung einer “Fenster-Funktion” auf die Ergebnisse eines Cross-Joins (mit mehreren Milliarden Datensätzen) der Speicherbedarf und somit auch die Laufzeit sehr stark an. Dafür schien ein Sortiervorgang verantwortlich zu sein, der für die Partitionierung der Daten erforderlich war. In diesem Fall war es beispielsweise deutlich effizienter, eine separate Abfrage zu schreiben, in der die Daten entsprechend gruppiert zusammengefasst werden und das Ergebnis dann in einem zusätzlichen Join weiter zu verwenden.
Fazit
Für die Effizienz der Exasol ist es entscheidend, dass immer die “richtigen” Daten im Speicher vorhanden sind und das DBMS möglichst wenig swappen muss. Im Profiling konnten wir beobachten, dass das DBMS in der Regel nicht mehr benötigte Informationen erkannt und den Speicher entsprechend aufgeräumt hat – auch bei komplexen Abfragen mit mehreren Zwischenergebnissen.
Natürlich ist es auch in der Exasol möglich, “schlechte” Abfragen zu schreiben. Aber wir mussten uns tatsächlich zu keinem Zeitpunkt Gedanken über Indizes (es gibt bei der Exasol nicht einmal ein "CREATE INDEX"-Statement) oder die Angabe von irgendwelchen Hints für den Optimizer machen – vor allem in Projekten und Systemen, die sich durch viele, unstrukturierte Abfragen auszeichnen, ein nicht zu vernachlässigendes Feature.
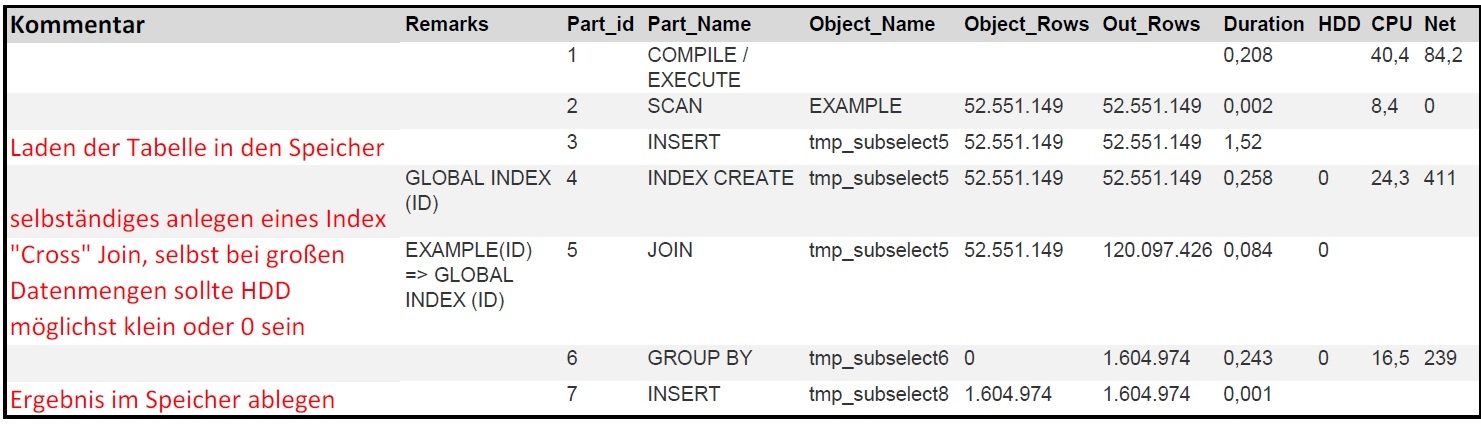
Für das konkrete Projekt konnten wir auf dieser Infrastruktur die Gesamtlaufzeit tatsächlich auf etwa 18 Stunden reduzieren und damit ein zentrales Ziel erreichen.
Für jeden, der die Exasol einfach mal ausprobieren möchte, stellt Exasol eine kostenlose und auch kommerziell nutzbare Edition zum Download bereit. Diese ist dann allerdings nicht clusterfähig und begrenzt auf 200 GB Arbeitsspeicher – doch für den ein oder anderen sicher einen Test wert.
Kommentare