
Relationale Datenbanken sind de facto Standard. Aufgrund einer breiten Erfahrungsbasis genießen sie eine hohe Akzeptanz in der Industrie. So ist es nicht verwunderlich, dass in fast jedem Unternehmen mit IT-Abteilung eine oder mehrere relationale Datenbanken zu finden sind.
Soll in einem solchen Unternehmen eine neue Anwendung entwickelt werden, die ihre Daten in einer Datenbank ablegt, so ist die Verwendung einer vorhandenen, relationalen Datenbank häufig vorgegeben und steht nicht zur Diskussion. Doch das ist nicht immer die beste Entscheidung.
JOIN-Probleme: Grenzen relationaler Datenbanken
Relationale Datenbanken sind für viele, aber nicht alle Anwendungsfälle eine gute Wahl, haben sie doch ihre Grenzen. Bei der Erstellung eines konkreten Datenbankschemas müssen die zu speichernden Daten normalisiert werden, um Redundanzen zu vermeiden. Das resultiert üblicherweise in einer gewissen Menge von Datenbanktabellen, deren Daten über Fremdschlüssel oder Verbindungstabellen miteinander in Beziehungen gebracht werden.
Beim Abfragen dieser Daten wird selten nur eine Tabelle herangezogen. Im Normalfall müssen Daten aus mehreren Tabellen gleichzeitig auslesen werden. Das zugehörige SQL-Statement benutzt hierzu JOIN-Operationen, um die über mehrere Tabellen verteilten Daten korrekt zusammen zu führen. Das ist notwendig, weil weder die relationale Datenbank noch die zugehörige Abfragesprache SQL das Konstrukt einer „Beziehung“ kennen, die bereits in der Datenbank materialisiert ist. Beziehungen werden zur Laufzeit, also zur Abfragezeit auf Basis der gesetzten Fremdschlüssel mittels JOIN-Operationen ermittelt. Diese JOIN-Operationen sind aber CPU- und speicherintensiv, d. h. sie verschlechtern die Performance. Je mehr Tabellen in einer Abfrage miteinander „gejoined“ werden und je mehr Daten in den einzelnen Tabellen gespeichert sind, desto länger dauert die Verarbeitung einer solchen Abfrage – unter Umständen mehrere Minuten bis Stunden. Dieser Umstand ist unter dem Begriff „JOIN-Problem“ bekannt. In einem solchen Fall kann das Setzen von sinnvollen Indizes, Partitionierung und Denormalisierung helfen, die Performance zu verbessern. Vollständig lösen lässt sich das JOIN-Problem dadurch aber nicht.
Wenn also eine größere Datenmenge, bei der es vor allem auch auf die Beziehungen zwischen den einzelnen Daten ankommt, verarbeitet werden muss, kann eine Graphendatenbank die bessere Wahl sein, spannen die zu verarbeitenden Daten inkl. ihrer Beziehungen in der Regel doch einen Graphen auf. Im Folgenden möchte ich die Graphendatenbank Neo4j als Alternative zu relationalen Datenbanken näher vorstellen.
Entwicklung und Modellierung mit Neo4j
Will man auf Basis der Open-Source-Graphendatenbank Neo4j entwickeln, benötigt man, wie für jede andere Datenbank auch, einen entsprechenden Treiber und Dokumentation. Treiber existieren für mehrere Programmiersprachen. Neben Java, Javascript, Phyton, .NET werden von der Neo4j-Community weitere Programmiersprachen unterstützt. Zusätzlich bietet Neo4j eine REST API, die JSON für Anfragen und Antworten über HTTP verwendet und so auch mit Programmiersprachen verwendet werden kann, für die es keine dedizierten Treiber gibt. Eine gute Dokumentation und eine aktive Community, die Fragen schnell beantwortet, rundet die Sache ab.
Wie jede Graphendatenbank speichert Neo4j Daten als Knoten und Beziehungen als Kanten.
In der Abbildung 1 ist ein kleiner Graph abgebildet, in dem die Beziehungen zwischen Romeo und Julia und der Stadt Verona modelliert werden. Dieser Graph enthält schon einige Erweiterungen, die die Graphendatenbank Neo4j ermöglicht. So können Knoten und Kanten zusätzliche Eigenschaften bekommen. Zum einen sind das Labels wie „:Person“, „:LIEBT“ oder „:Stadt“ und zum anderen Properties, die aus Key-/Value-Paaren bestehen. Ein Knoten kann dabei beliebig viele Labels und Properties enthalten, eine Kante nur ein Label und beliebig viele Properties.
Mit diesen wenigen Mitteln ist es möglich, Daten und deren komplexe Zusammenhänge als ausdrucksstarken Graph zu modellieren. Die Modellierung eines solchen Property Graph Model kann in den meisten Fällen direkt in eine konkrete Datenbank umgesetzt werden. Der Grund hierfür ist, dass die semantische Kluft zwischen der Modellierung und der resultierenden Datenbank, im Gegensatz zur Modellierung eines relationalen Datenbankmodells, sehr klein ist. Zudem sind sowohl die Modelle als auch die Datenbank gut verständlich – nicht nur für Experten wie Domänenspezialisten, sondern auch für normale Benutzer.
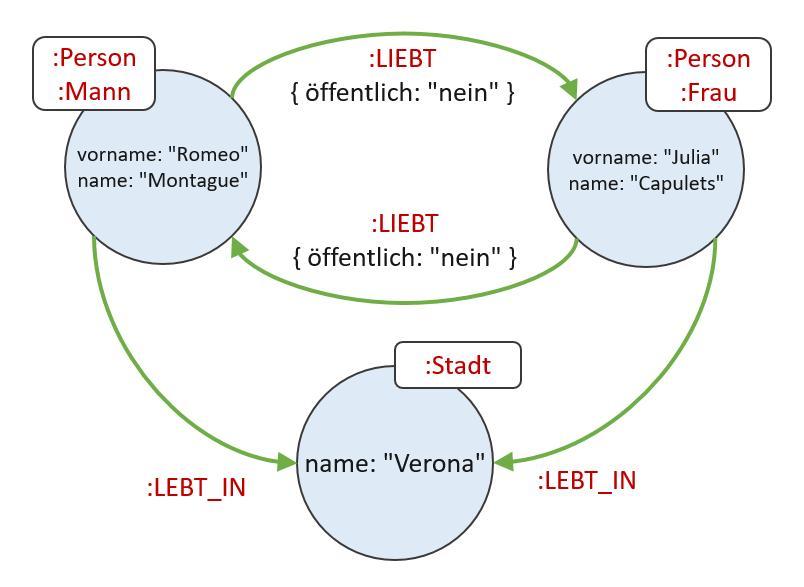 Abbildung 1: Neo4j-Graph
Abbildung 1: Neo4j-Graph
Abfragesprache Cypher: Von der textuellen Notation zum Graph
Die Graphendatenbank Neo4j bringt mit Cypher eine eigene deklarative Abfragesprache mit. Diese orientiert sich an SQL und bietet graphspezifische Funktionen. Ein Teil der Notation bildet die graphischen Notation von Graphen textuell ab:
- Knoten werden als
(...)dargestellt - Kanten werden als
–[...]->dargestellt
Will man in der textuellen Notation z. B. die Beziehung zwischen Romeo und Julia aus dem weiter oben genannten Beispielgraphen ausdrücken, dann erfolgt das über den String:
(:Person {vorname:‘Romeo‘}) –[:LIEBT]-> (:Person {vorname:‘Julia‘})
Solche Strings definieren Pattern, die Subgraphen innerhalb des Gesamtgraphen referenzieren. Das obere Pattern referenziert die beiden Personen-Knoten von Romeo und Julia und die LIEBT-Kanten dazwischen.
Mit dieser Notation ist es möglich, beliebige Subgraphen und Pfade innerhalb des Gesamtgraphen zu spezifizieren, für die man sich interessiert. Die Cypher-Abfrage
MATCH (p1:Person {vorname:‘Romeo‘})–[:LIEBT]->(p2:Person {vorname:‘Julia‘})
RETURN p1, p2;
liefert den Subgraphen aus Abbildung 2.
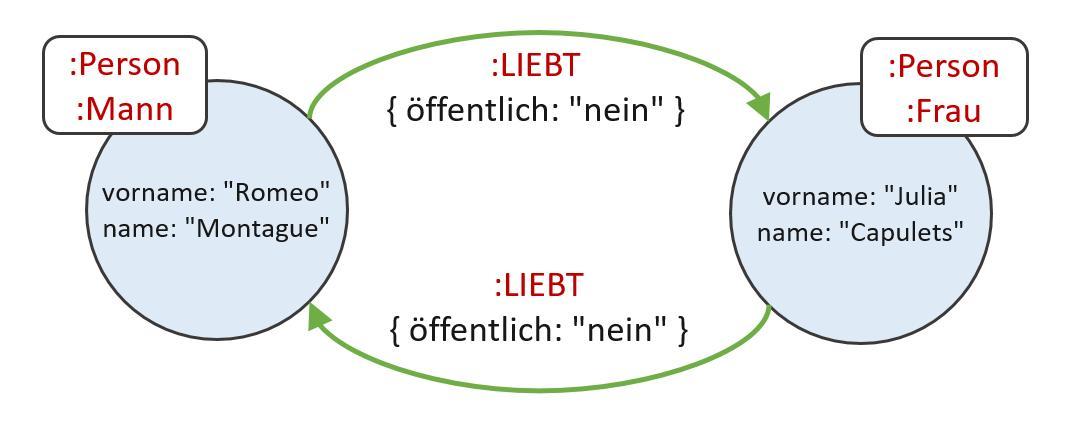
Abbildung 2: Subgraph
Mit Cypher lassen sich natürlich auch Knoten und Kanten anlegen, ändern und löschen, komplexe Abfragen formulieren, Ergebnismengen als Graph oder in textueller Form wiedergeben und vieles mehr.
Wer bereits SQL kennt, wird sich sehr schnell in Cypher einarbeiten können. Dabei hilft auch die sehr gute Cypher-Dokumentation.
Vorteile von Graphdatenbanken wie Neo4j
Performance
Wie schon weiter oben erwähnt, spielen Graphendatenbanken ihre Stärke dort aus, wo es um die Verarbeitung von Beziehungen bei großen Datenmengen geht. Weil Beziehungen als Konstrukt sowohl von der Datenbank als auch von Cypher direkt unterstützt werden, sind JOIN-Operationen nicht notwendig. Die Traversierung eines Graphen ist dadurch sehr effizient.
Agilität
In der Graphendatenbank Neo4j kann jeder einzelne Knoten und jede einzelne Kante im Extremfall eigene Labels und eigene Properties besitzen. Bestehenden Knoten können Labels und Properties hinzugefügt oder gelöscht werden. Mit einigen Einschränkungen gilt das auch für Kanten.
Diese Möglichkeiten sind bei einem agilen Vorgehen von Vorteil, weil bei neu zu speichernden Daten nicht wie bei einer relationalen Datenbank aufwändig das Datenbankschema angepasst und Altdaten migriert werden müssen. Damit ist man in der Lage die Datenbank mit weniger Aufwand und dadurch schneller an die sich veränderten Anforderungen anzupassen – und das nicht nur während der Entwicklung, sondern auch während des produktiven Betriebs. Damit kann schneller auf Änderungen im Geschäftsumfeld reagiert und die Time-to-Market reduziert werden.
Einfachheit
Die Modellierung von Daten und ihren Beziehungen (z.B. auf einem Whiteboard) ist in vielen Fällen recht intuitiv. Das Ergebnis lässt sich danach häufig 1:1 in eine Datenbank überführen. Ebenso ermöglicht die Abfragesprache Cypher durch die Verwendung von Patterns das Schreiben von leicht verständlichen Cypher-Anweisungen. Diese sind in der Regel auch deutlich kürzer als vergleichbare SQL-Statements.
Enterprise Ready
Damit eine Datenbank im Enterprise-Umfeld Verwendung findet, muss sie einige Voraussetzungen erfüllen. Ein Hauptkriterium sind die ACID-Eigenschaften. Neo4j ist ACID-fähig. Darüber hinaus wird auf Hochverfügbarkeit viel Wert gelegt. Neo4j bietet hier eine Hochverfügbarkeitsarchitektur wie sie in Abbildung 3 dargestellt wird. Neben mehreren Neo4j-Instanzen, die als Master oder Slaves betrieben werden, spielen Komponenten wie der ZooKeeper Service, ein Cluster Manager und ein vorgeschalteter Load Balancer wichtige Rollen. Mit dieser Architektur wird eine Fehlertoleranz und die Skalierbarkeit des Gesamtsystems erreicht.
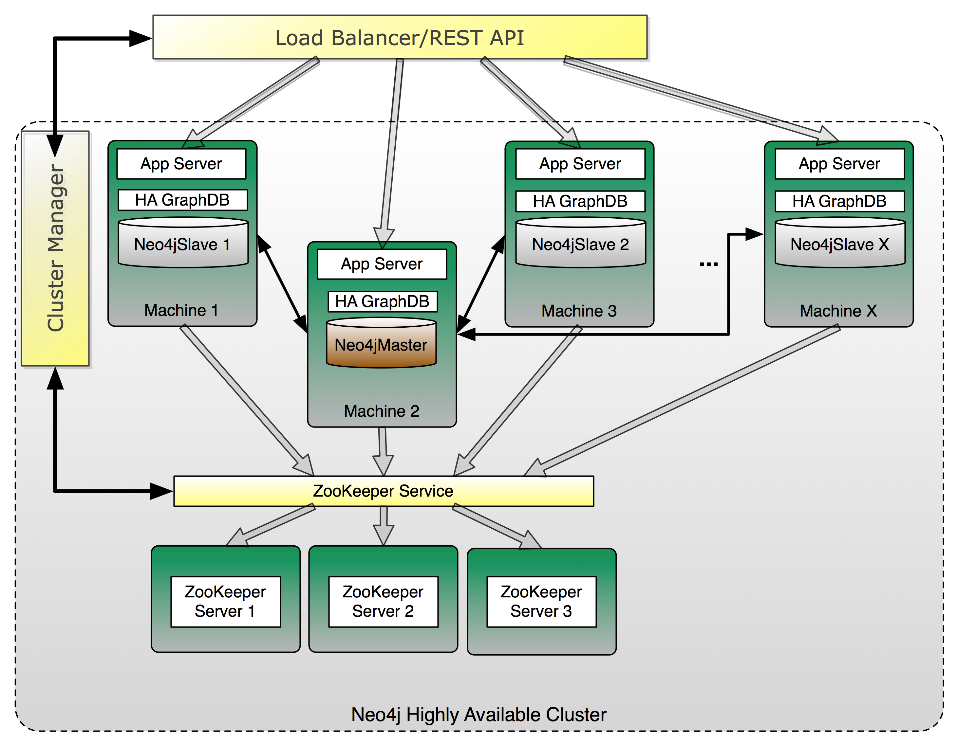
Abbildung 3: Hochverfügbarkeitsarchitektur von Neo4j
Fazit
Wer Performance-Probleme mit seiner relationalen Datenbank hat und diese nicht ohne weiteres lösen kann, sollte darüber nachdenken, ob eine Graphendatenbank wie Neo4j nicht besser für den vorliegenden Anwendungsfall geeignet wäre.
Es lohnt sich aber auch, Neo4j einfach mal so auszuprobieren. Mit der Community Edition ist Neo4j schnell installiert und gestartet. Die integrierte Dokumentation und das Tutorial führen den Einsteiger Schritt für Schritt in die Konzepte der Graphendatenbank Neo4j und der Abfragesprache Cypher ein. So findet man sich schnell bei der Erstellung einer eigenen Datenbank wieder, was nebenbei auch eine Menge Spaß macht.
Kommentare